User Scenarios¶
The user requirements outlined in this document drove much of the process for identification of the DataONE Functional Use Cases described elsewhere. The functional use cases were identified and prioritized over a series of meetings funded by the NSF sponsored “Virtual Data Center” (VDC) INTEROP project.
US 01. Core Functionality (proposed)¶
DataONE provides the distributed framework (which is comprised of Member and Coordinating Nodes as illustrated below), sound management, and robust technologies that enable long-term preservation of diverse multi-scale, multi-discipline, and multi-national observational data. DataONE initially emphasizes observational data collected by biological (genome to ecosystem) and environmental (atmospheric, ecological, hydrological, and oceanographic) scientists, research networks, and environmental observatories. DataONE will be domain agnostic, progressively expanding to broader domains and building on infrastructure and interoperability with DataNet partners.
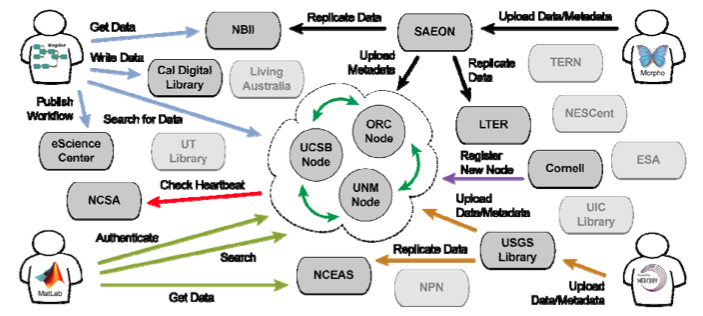
DataONE Member Nodes form a robust, distributed network via coordinating services provided by a set of Coordinating Nodes (i.e., Oak Ridge Campus, UC-Santa Barbara, and University of New Mexico) arranged in a high-availability configuration. Scientists and citizens interact with Member Nodes (e.g., South African Environmental Observation Network, California Digital Library, USGS National Biological Information Infrastructure) through software tools that utilize standardized interfaces. This structure supports many different usage scenarios, such as data and metadata management and replication (e.g., using Morpho [black arrows] or the Mercury system [orange arrows]), as well as analysis and modeling (e.g., using commercial software like Matlab [light green arrows] and open-source scientific workflow systems like Kepler [blue arrows]). Coordinating Nodes perform many basic indexing and data replication services to ensure data availability and preservation (e.g., node registration [purple arrow] and monitoring via heartbeat services (red arrow]).¶
US 02. Value Added Services (proposed)¶
DataONE is not the end, but rather the means to enable scientists and citizens to address and better understand the difficult and complex biological, environmental, social, and technological challenges affecting human, ecosystem, and planetary sustainability. The comprehensive cyber-infrastructure allows novel questions to be asked that require harnessing the enormity of existing data and developing new methods to combine and analyze diverse data resources (see figure below).
DataONE will accomplish its goals by making scientists, students, librarians, and citizens active participants in the data life cycle, especially the data preservation process. By supporting community derived interoperability standards and incorporating new value-added and innovative technologies (e.g., for semantic and geospatial information, scientific workflows, and advanced visualization) into the scientific process, DataONE will facilitate sophisticated data integration, analysis, interpretation, and understanding. A strong education and outreach program focuses on scientists and students learning to better and more easily manage, preserve, analyze, and visualize Earth observational data. Citizen scientists are actively engaged in data preservation and scientific discovery through their involvement in programs such as the USA National Phenology Network (USA-NPN) and numerous Cornell Laboratory of Ornithology citizen science efforts (e.g., eBird, Project FeederWatch).
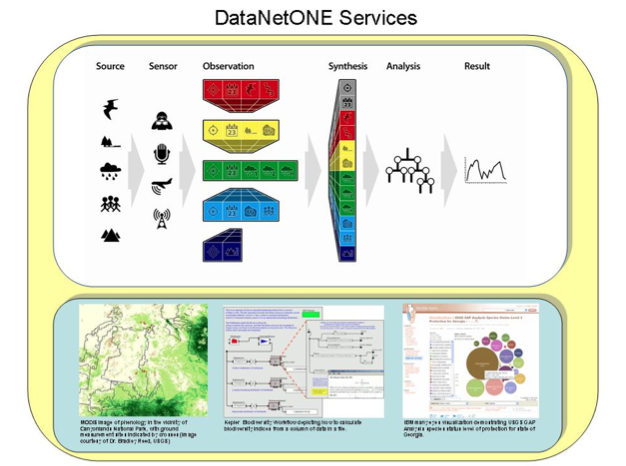
DataONE value-added services enable scientists to address novel questions through integrating disparate data sources (top), supporting geospatial data processing (lower left), and providing scientific workflow solutions like Kepler (lower middle) and high-level analyses and visualizations like IBM ManyEyes.¶
US 03. System Architecture (proposed)¶
The DataONE architecture must embrace the highly dispersed and independent nature of data collection activities relevant to the environmental and earth sciences. Data are collected by tens of thousands of scientists around the world who have the expertise to describe and archive these data, as well as curate them. Attempting to centralize this curation function is inherently untenable and will not scale. Thus, DataONE will achieve both scalability and sustainability through a highly distributed system architecture (Figures from “Core Architecture” and below) that utilizes the DataONE Service Interface to access uniform services provided and used by three types of cyber-infrastructure: (1) Member Nodes located at institutions distributed throughout academia, libraries, government agencies, and other organizations that provide local data storage, curation, and metadata for a set of data resources that are collected or affiliated with that institution; (2) Coordinating Nodes that are geographically-distributed to provide a high-availability, fault-tolerant, and scalable set of coordinating services to the Member Nodes, including a complete metadata index and data replication services for all data in all Member Nodes; and (3) an Investigator Toolkit that provides a complete and evolving set of tools for data and metadata management by scientists and curators throughout the entire data life cycle (Figure 3). Initially, there will be three Coordinating Nodes geographically dispersed at ORC, UNM, and UCSB. A small number of additional Coordinating Nodes may be implemented as DataNetONE expands in scope, sustainable funding, and international presence.
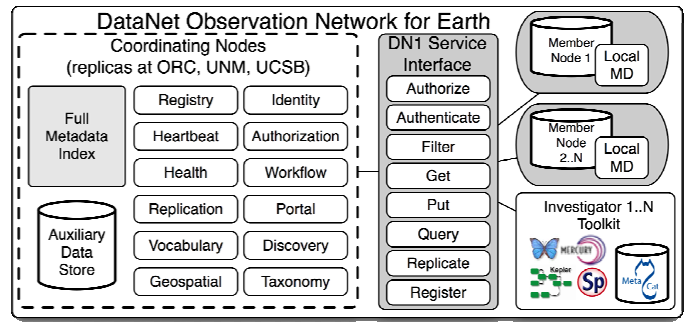
Main features of the DataNetONE architecture, emphasizing distributed data storage at Member Nodes and metadata indexing and services provided by Coordinating Nodes. Communication between Member Nodes (e.g., for replication), between Member Nodes and the Investigator Toolkit (e.g., for inserting data), and between Member Nodes and Coordinating Nodes (e.g., for metadata indexing) is all mediated via a common DataNetONE Service Interface that spans all node types.¶
US 04. Spread and Impact of Invasive Species¶
Invasive species are:
Expensive - response estimates up to $138bn per year in the US.
Complex - many interactions and factors determine invasiveness and impact
Overwhelming - border and import controls struggle with sheer volume of material and confusion for access and collation of relevant biodiversity information
The outcome is suboptimal consideration of potential biotic risks associated with imports of new products, packing, shipping methods or products from new regions.
DataONE eliminates confusion related to information access and integration, providing domain relevant knowledge to researchers, border agents and to inform policy makers on potential impact or savings associated with new or ongoing trade relationships.
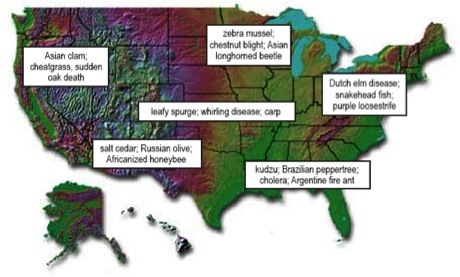
Some examples of economically important invasive species in the United States.¶
Specifically, DataONE addresses:
Volume – combines majority of digitized species occurrence information through GBIF,NBII, IABIN and other partnerships
Structure - efficient access to data, metadata, and workflows from ecological, environmental, socio-economic data, and related studies and assessments (e.g. Metacat, Dryad, Mercury, NBII)
Dynamic - service infrastructure for interpolation of data (e.g. species occurrence points to distribution regions and environmental requirements)
Knowledge - semantic assisted discovery and integration of indirectly associated data
Social interactions – transparent communications between researchers and implementers providing latest information possible for regions taxa, and trade routes, and fora of product reviews, models, and other related information

Japanese honeysuckle (Lonicera japonica) was brought to the United States from Asia as ground cover to prevent erosion. As an invasive species, it can topple small trees and schrubs by its weight. The resulting change in forest structure may negatively affect songbird populations.¶