Log Aggregation Overview¶
See subversion log for revision information.
Introduction¶
The Log Aggregation Facility (LAF) harvests event log information from all Member Nodes registered with a Coordinating Node and aggregates this information into a Solr index that contains information from all member nodes. The Solr index can be queried to create reports of usage statistics for the DataONE network or individual Member Nodes. A description of the data harvested from MNs is described here: LoggingSchema.html
LAF relies on several technologies: Quartz Scheduler, Hazelcast Data Distribution, Metacat Repository Storage, and the Solr Search platform.
The DataONE use cases are described here:
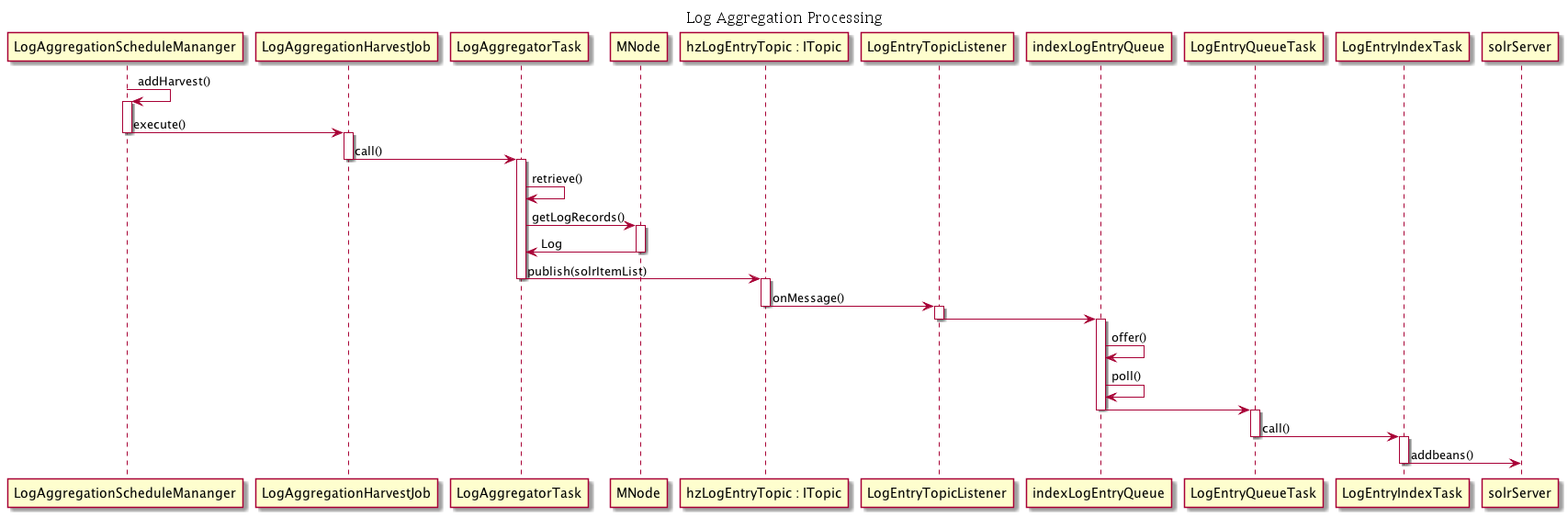
An overview of LAF processing is shown in Figure 1: Log Aggregation Overview
Figure 1. Log Aggregation Overview
Installation¶
LAF software is installed from the dataone-cn-processdaemon and dataone-cn-solr Debian packages.
LAF is started when the Unix service /etc/init.d/d1_processing is launched. LogAggregationScheduleManager is initialized by Spring when d1_processing runs the bootstrap class org.dataone.cn.batch.daemon.SchedulerDaemon. All LAF related beans are configured in /etc/dataone/process/applicationContext.xml.
LAF does not require any manual configuration before it can be run, however Metacat must be installed and configured before LAF starts.
Several LDAP attributes are used to control the execution of LAF, so if necessary the following LDAP entries can be manually edited to alter execution of LAF. This may be useful for testing purposes. Table 1 shows the LDAP attributes in the directory dc=dataone,dc=org,cn=urn:node:<nodeName> directory that LAF uses
Table 1 LDAP entries
Attribute Name
Value
Purpose
d1NodeAggregateLogs
TRUE or FALSE
Enable/Disable this node for harvesting
d1NodeLogLastAggregated
ISO 8601 date
Last time this MN was harvested
Log Recovery Processing¶
The Java class LogAggregationScheduleManager coordinates all scheduling of jobs for LAF. This class first checks if any other CN has more current log information and if so a recovery job is scheduled to query the other CNs for newer log records.
Log Harvest Processing¶
Then LogAggregationScheduleManager schedules recurring Quartz job (every 24 hours) for LogAggregationHarvestJob which handles running the tasks that harvest log data from the MNs.
Next a Hazelcast listener is registered for the top thehzLogEntryTopic. When log entries are returned from MNs they will posted to Hazelcast so that they are distributed to every CN.
A Hazelcast systemmetadata listener is also registered so that certain changes to mutable systemmetata fields (see System Metadata Updates for details).
The queue indexLogEntryQueue is then setup when the listener LogEntryTopicListener is called. This queue is how tasks that perform the log aggregation and tasks that perform the log indexing communicate.
LogAggregationHarvestJob runs the task LogAggregatorTask that queries each MN by calling mn.getLogRecords and retrieving up to 1000 event log records at a time, starting after the last date retrieved that was recorded by the last run, if any.
LogAggregatorTask then modifies each harvested record by adding the following fields: isPublic, dateAggregated, nodeId, readPermissions, formatId, formatType, size, rightsHolder, country, region, city, geohash_1 - geohash_9, location. These records are then published to the Hazelcast topic hzLogEntryTopic so that each CN that is running LAF will have it’s LogEntryTopicListener fire, which published them to the queue indexLogEntryQueue. In this way one CN harvests a single MN at a time, and the processing of those records is synced with the other CNs.
On the indexing side of processing, LogEntryQueuManager is initialized by Spring when d1_processing init script is run executes the task LogEntryQueueTask that reads and processes entries from the logEntrySolrItemList when this queue has accumulated 100 entries.
LogEntryQueueTask then starts task LogEntryIndexTask which sends entries to Solr for indexing.
Figure 2. Log Aggregation Processing
System Metadata Updates¶
In addition to processing harvested records, when an entry in the Hazelcast Systemmetadata map is added or updated, SystemMetadataEntryListener runs. This may happen when one of the mutable fields in systemmetadata changes, such as formatId. In this event, all event log records for that pid must be updated, so SystemMetadataEntryListener retrieves these records, updates them with the current information in systemmetadata and then updates the entries and then publishes them to the IndexLogEntrySolrItem queue, so that they are processed in the same way as new Event Log records.
Figure 3. System Metadata Listener
Solr Index¶
Table 2 shows the fields contained in the Event Log Solr index
Table 2. Solr index schema
Event Log Index Schema¶
Name |
Solr Type |
Comment |
|---|---|---|
id |
string |
added after harvest |
dateAggregated |
date |
added after harvest |
isPublic |
boolean |
added after harvest, obtained from systemmetadata |
readPermission |
string |
added after harvest, obtained from systemmetadata, filtered during query |
entryId |
string |
obtained from MN event log |
pid |
string |
added after harvest, obtained from systemmetadata |
ipAddress |
string |
obtained from MN event log, filtered during query |
userAgent |
string |
obtained from MN event log |
subject |
string |
obtained from MN event log, filtered during query |
event |
string |
obtained from MN event log |
dateLogged |
date |
obtained from MN event log |
nodeId |
string |
obtained from MN event log |
rightsHolder |
string |
added after harvest, obtained from systemmetadata, filtered during query |
formatId |
string |
added after harvest, obtained from systemmetadata |
formatType |
string |
added after harvest, obtained from systemmetadata |
size |
slong |
added after harvest, obtained from systemmetadata |
country |
string |
added after harvest, determined from ipAddress |
region |
string |
added after harvest, determined from ipAddress |
city |
string |
added after harvest, determined from ipAddress |
geohash_1 |
string |
added after harvest, determined from ipAddress |
geohash_2 |
string |
added after harvest, determined from ipAddress |
geohash_3 |
string |
added after harvest, determined from ipAddress |
geohash_4 |
string |
added after harvest, determined from ipAddress |
geohash_5 |
string |
added after harvest, determined from ipAddress |
geohash_6 |
string |
added after harvest, determined from ipAddress |
geohash_7 |
string |
added after harvest, determined from ipAddress |
geohash_8 |
string |
added after harvest, determined from ipAddress |
geohash_9 |
string |
added after harvest, determined from ipAddress |
location |
location |
added after harvest, determined from ipAddress |
inFullRobotList |
boolean |
added after harvest, determined based on log processing for COUNTER compliance |
inPartialRobotList |
boolean |
added after harvest, determined based on log processing for COUNTER compliance |
isRepeatVisit |
boolean |
added after harvest, determined based on log processing for COUNTER compliance |
Solr Query Processing¶
The Event Log Solr index can be queried from the service endpoint https://cn.dataone.org/cn/v1/query/logsolr, for example, the following query will return read counts for each node in the network:
https://cn.dataone.org/cn/v1/query/logsolr/select?q=event:read&facet=true&facet.field=nodeId
The Event Log Solr index requires authenticated access, because some fields in the log entries contain sensitive information, as shown in Table 2.
Solr queries are inspected and rewritten by SolrLoggingHandler such that counts for Solr entries will be included only if the entries are publicly accessible, or the user is a CN administrator or the caller’s identify has access privileges to the pids of the entries.
If the requesting session has a certificate then a list of authorized subjects is obtained from LDAP and access is based on the authorized subjects. Since the Solr index contains access information from systemmetadata, the same access rules that apply to systemmetadata will apply to the event log.
If the authenticated user is the CN administrator then the entire contents of each SOLR document are available in the SOLR result.
Example Queries¶
A description of how to query the Event Log Solr Index, please see the document UsageStatistics.html.
![]()
Table of Contents
Related Topics
- Documentation Overview
- Previous: Logging Schema
- Next: DataONE Usage Statistics